第13章 地理院・国交省データの利用
標高メッシュデータ
データの下準備
地理院からデータをダウンロードするとzipで圧縮されている.中にはXML形式のファイルが入っている. これを扱いやすくするために緯度,経度,標高のxyz形式にするため, 同じく地理院からダウンロードできる基盤地図情報ビューアをインストールする. これを起動して開く画面に,標高メッシュのzipファイルをドラッグすると地形が描画される.
「エクスポート>標高メッシュをシェープファイルへ出力」を選んで開く画面で,(1)直角座標系に出力するチェックを外し,(2)出力ファイル名の拡張子を「.xyz」に変える.拡張子がデフォルトのままだと,後で開いても文字化けして読み取れなかった.ただし(1)はナントカ座標系とやらのxyz座標で出力したいのならチェックが必要(図*※相互参照無効*).
基盤地図情報ビューアによるxyz形式への変換時の画面.(標高データ: 国土地理院基盤地図情報数値標高モデル)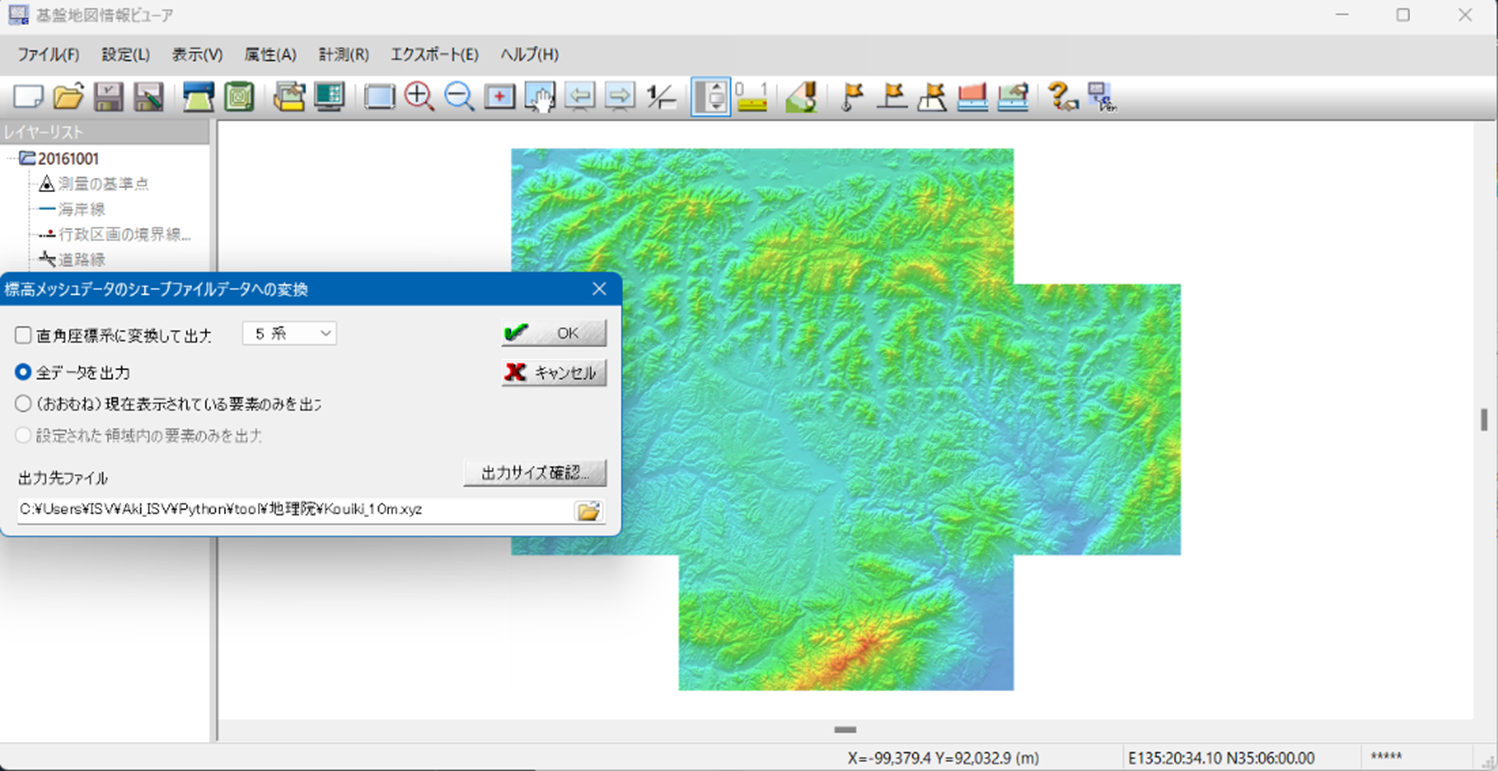
データの読み込み
作成したxyzファイルは,numpyを使ってcsvと同じ方法で読み込める. すなわちdelimiterを「,」にしてnp.loadtxt()である. ただそのままだと最初の列に行番号が入っているので, 必要なxyzの列だけを取り出すためにusecols=[1,2,3]としてcolumnを指定すると良い.
dat = np.loadtxt(r"out.xyz",
delimiter=",",
usecols=[1,2,3])
国交省による道路等の線データの利用
道路や鉄道路線などのデータをダウンロードすると,シェープファイルやgeojsonファイルなどが入っている.これをライブラリを使って取り込んでプロットする.
jsonライブラリの利用
(1)import json. (2)open(<.geojson>, ‘r’, encoding=<utf_8_sig>) (3)json.load(openfile) (4)条件で絞込.(5)リストに格納してプロット.
ダウンロードしたファイルのutf-8フォルダー中にある方の.geojsonデータを使う.直上のフォルダにも.geojsonがあるがencodingを何にすれば良いのかわからず使えなかった.‘cp932’にしてみたがエラーが出た.
import json
train_path_gj = "鉄道/utf8/N02-21_RailroadSection.geojson"
jopen = open(train_path_gj,
'r',
encoding = 'utf_8_sig'
)
dat_j = json.load(jopen)
kobe = []
# ftr = []
for data in dat_j["features"]:
if "神戸電鉄" in data["properties"]["N02_004"]:
# ftr.append(data["properties"]["N02_004"])
tmp = data["geometry"]["coordinates"]
kobe.append(tmp)
(略)
for i in range(len(kobe)):
fig.plot(
data = kobe[i],
style = 'f0.2c/0.1c',
pen = '0.5p'
)
国交省からダウンロードした鉄道データをjsonライブラリを用いて読み込みプロットした結果.(標高データ: 国土地理院基盤地図情報数値標高モデル; 鉄道路線データ: 国土交通省国土数値情報)
geopandasの利用
gpd.read_file(<utf-8のgeojsonデータ>, encoding='utf_8_sig')
condaでインストールできるライブラリgeopandasを使う方法.(1)shpファイルを使う場合:
train_path = "鉄道/N02-21_RailroadSection.shp"
df = gpd.read_file(train_path_gj, encoding='cp932')
(2)geojsonファイルを使う場合:
import geopandas as gpd
train_path_gj = "鉄道/N02-21_RailroadSection.geojson"
df = gpd.read_file(train_path_gj, encoding='utf_8_sig')